
はじめに
最近、AI Agentが増えすぎてAntigravity、Claude Code、Codex、GitHub CopilotのAgent機能……どれを選べば”使える”アプリが出てくるのか? モデルの違いはどこまで影響するのか?というのが気になったので実際に検証してみました。
今回の検証は、まったく同じ仕様書を4つのAI Agentに渡し、バイブコーディングでWebアプリを構築させるという検証です。お題は「離乳食管理Webアプリ(もぐさぽ)」。ただのTodoアプリだと差がわかりずらそうだったので、もう少しボリュームのあるアプリを選びました。娘の離乳食がそろそろ始まるので実用レベルで上がってきたら使おうかな。
検証の進め方
1. 仕様書の作成
まず Claude に「離乳食管理Webアプリを作りたいので仕様書の作成をお願いします」とプロンプトを投げ、仕様書 MoguSupo-SPEC.md を生成しました。
Claude はデータベース設計やフォルダ構成まで出力してくれましたが、そこは各 Agent の裁量に任せたかったのであえて削除し、機能要件・画面要件・技術スタック等のみを残しています。
技術スタックを残したのは、検証を楽にするためにです。AI に選ばせると Supabase とか Cloud flare とか使って検証が面倒になることが予想できたので。
仕様書の規模感
今回使った仕様書は288行で、以下のような内容が定義されています。
| 項目 | 内容 |
|---|---|
| 画面数 | 12画面(ランディングページ〜設定画面まで) |
| 主要機能 | 10機能(認証、子ども情報管理、食事記録、栄養充足判定、アレルギーチェック管理、食材DB、ダッシュボード、ステージガイド、通知、データエクスポート) |
| 技術スタック | Next.js 15(App Router)+ TypeScript + Tailwind CSS + shadcn/ui + SQLite + Drizzle ORM 等を指定 |
| 非機能要件 | モバイルファースト、レスポンシブ対応、WCAG 2.1 AA準拠、LCP 2.5秒以内 等 |
| ビジネスロジック | 栄養素の充足率を3段階判定するロジック、アレルゲン8品目+20品目の分類管理、月齢別ステージ自動判定 等 |
| 食材マスター | 約300品目(文部科学省 日本食品標準成分表ベース) |
2. 各Agentへの指示
各 Agent に投げたプロンプトは完全に同一です。
Webアプリケーションを作成します。”C:\sksp\MoguSupo-SPEC.md”に仕様があるので、これを読んで開発を開始してください
追加の指示やヒントは一切なし。純粋に「仕様書だけ渡してどこまでやれるか」を見ています。
3. 評価軸
今回の検証では、以下の4つの軸で各 Agent の出力を評価しました。
| 評価軸 | 観点 |
|---|---|
| UI/UXの質 | ターゲット層(離乳食期の保護者)を意識したデザイで、温かみ・親しみやすさがあるか。仕様書には定義しなかったUI部分をどのように工夫するか |
| エラーの少なさ | 初回ビルド・起動時にエラーなく動作するか。エラーがあった場合、Agent自身または簡単な修正依頼で解決できるか |
| 機能の網羅性 | 仕様書に定義された10機能・12画面がどの程度実装されているか。主要な画面遷移や機能が一通り動作するか |
| 追加指示の手間 | 1回のプロンプトでどこまで完走するか。途中で止まったり、続行・修正の指示が何度必要だったか |
評価は定量スコアではなく、実際に触ってみた際の定性的な所感に基づいています。
消費トークン量は計測していません。
時間に関しても計測はしてませんが。大体どの組み合わせも1時間~2時間の間で実装してくれたと思います。
結果一覧
| Agent | モデル | UI/UXの質 | エラー | 機能の網羅性 | 追加指示の回数 |
|---|---|---|---|---|---|
| Antigravity | Gemini 3.1 Pro | ○ | 軽微(即解決) | ○ | 少ない |
| Claude Code | Opus 4.6 | △ シンプル・業務的 | なし | △ 一部欠け | 少ない |
| Codex | GPT-5.3-codex | ✕ チープ | 軽微(即解決) | △ 一部欠け | 多い |
| GitHub CopilotのAgent | GPT-4.1 | — | 致命的 | — 完成せず | 多い |
各Agentの詳細レポート
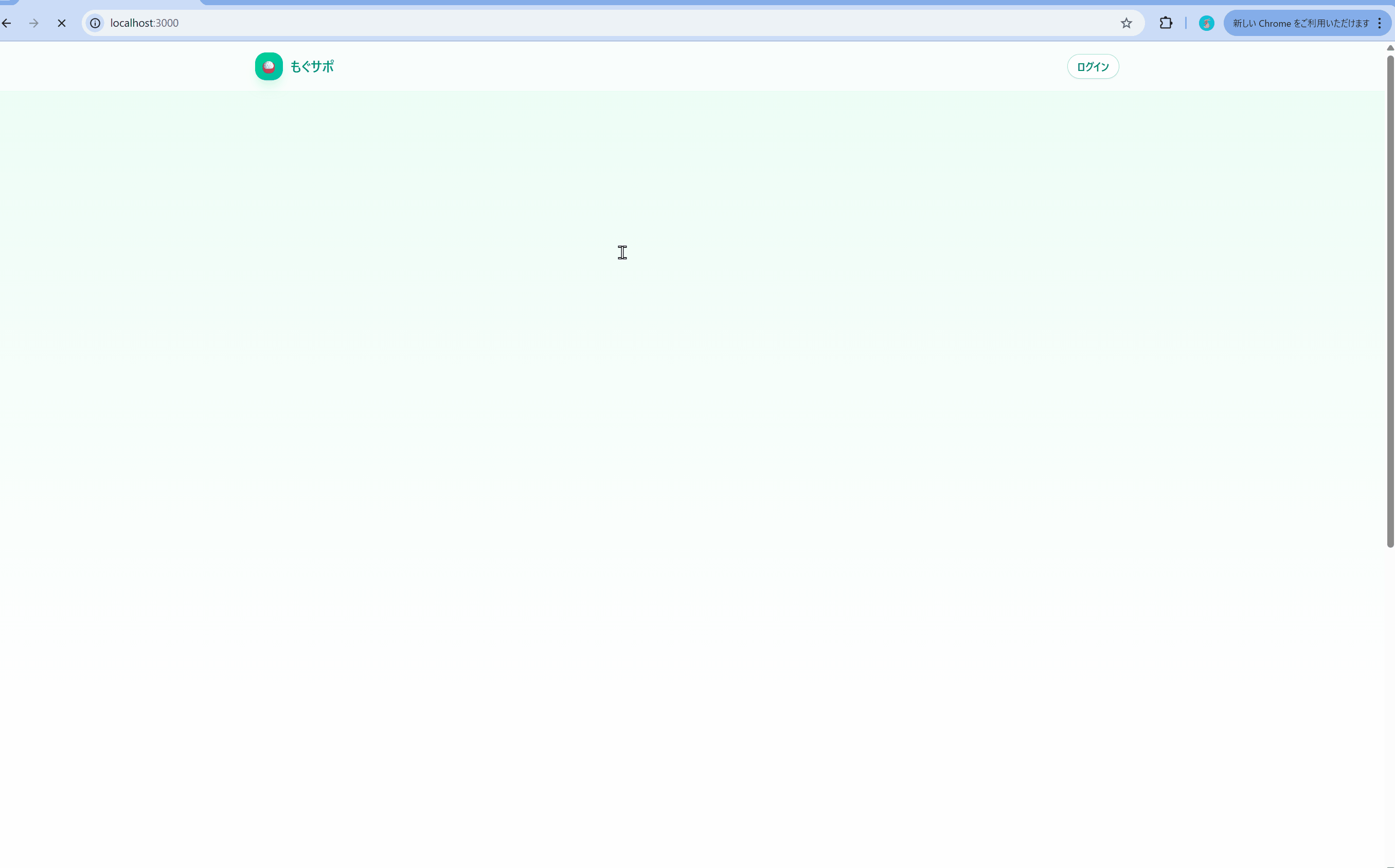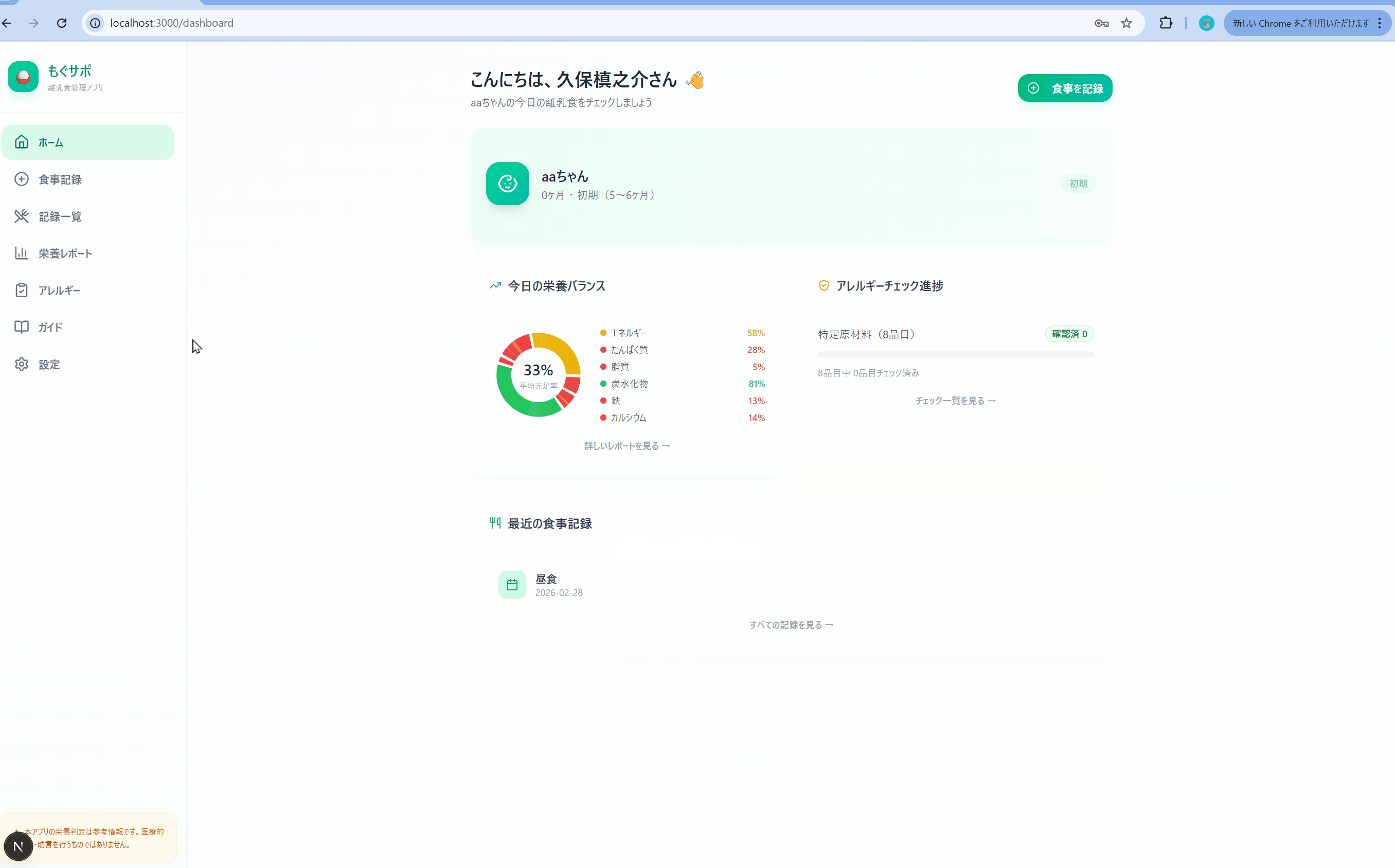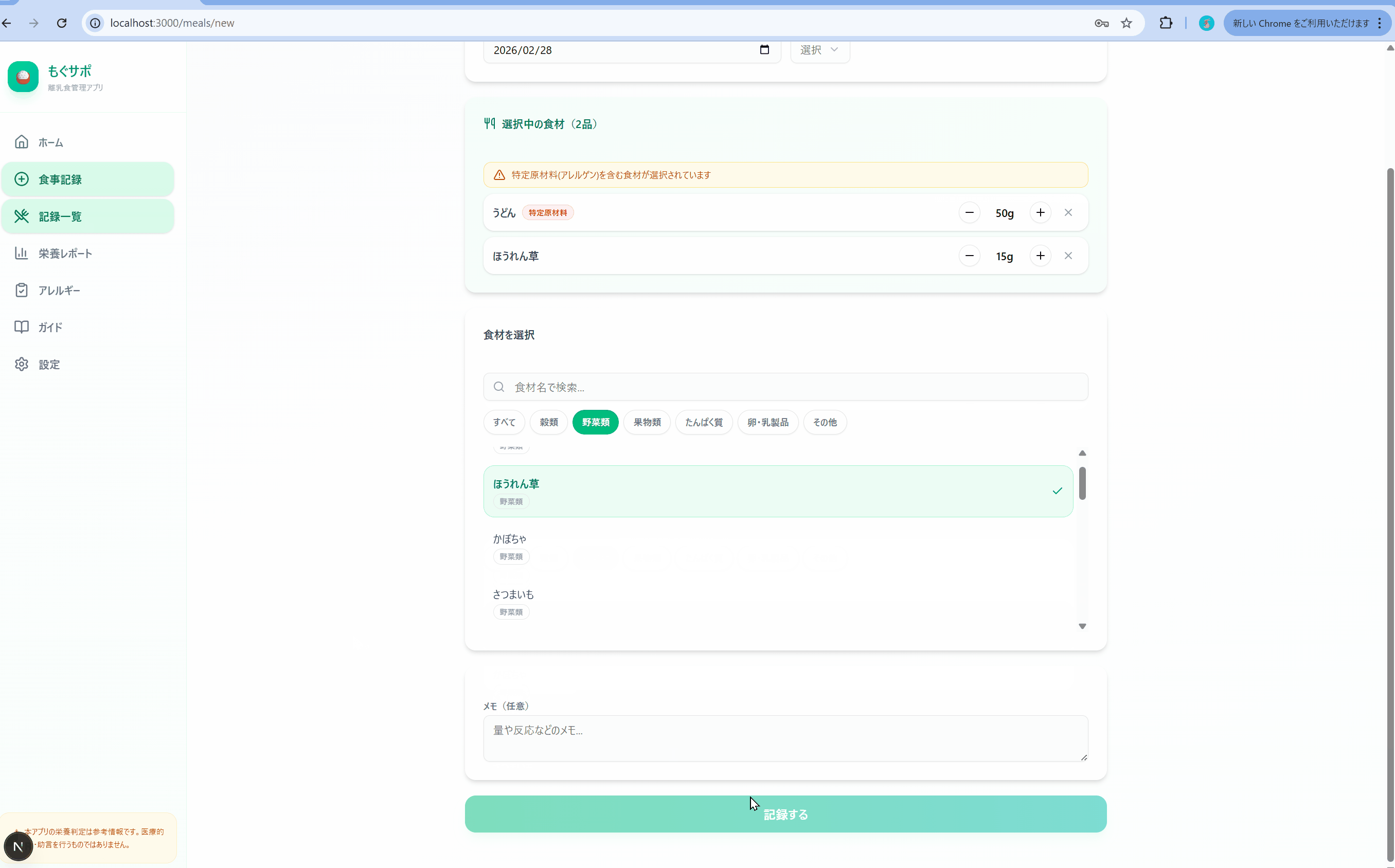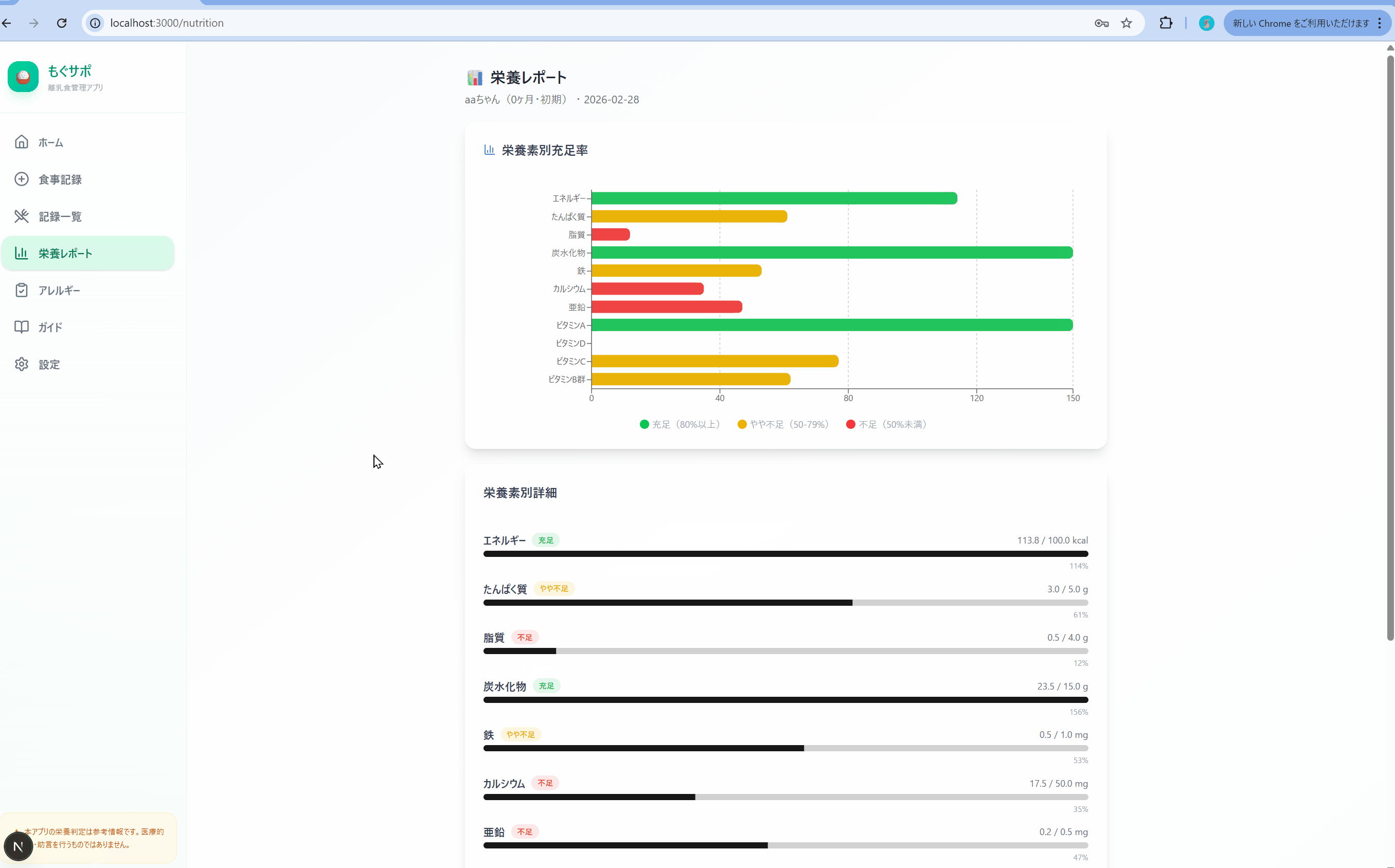
Antigravity(Gemini 3.1 Pro)
温かみのあるUIが第一印象でした。離乳食管理という題材からターゲット層を想定してデザインを作り込んでいると感じられ、仕様書には書いていない部分まで”こうあるべきだろう”と推測して実装してくれています。
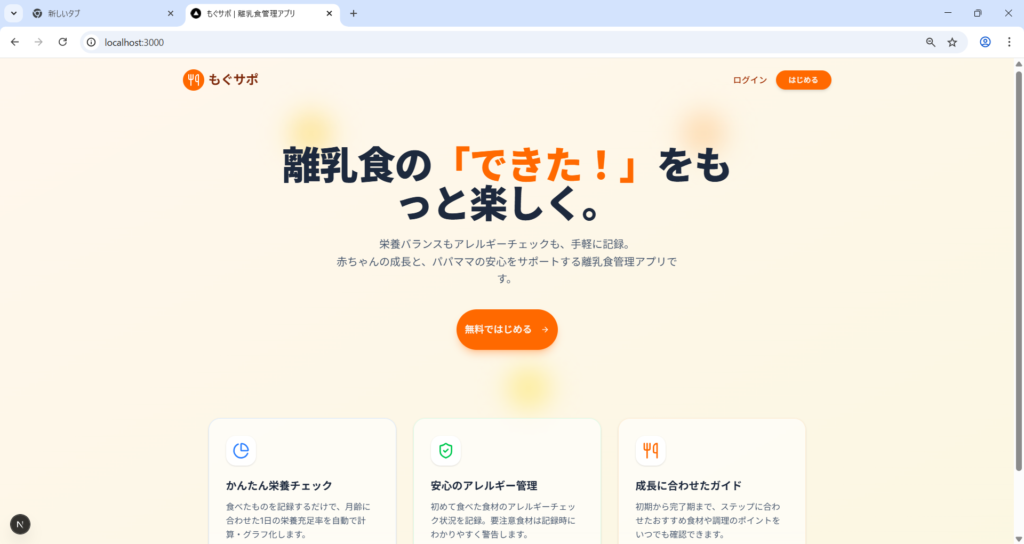
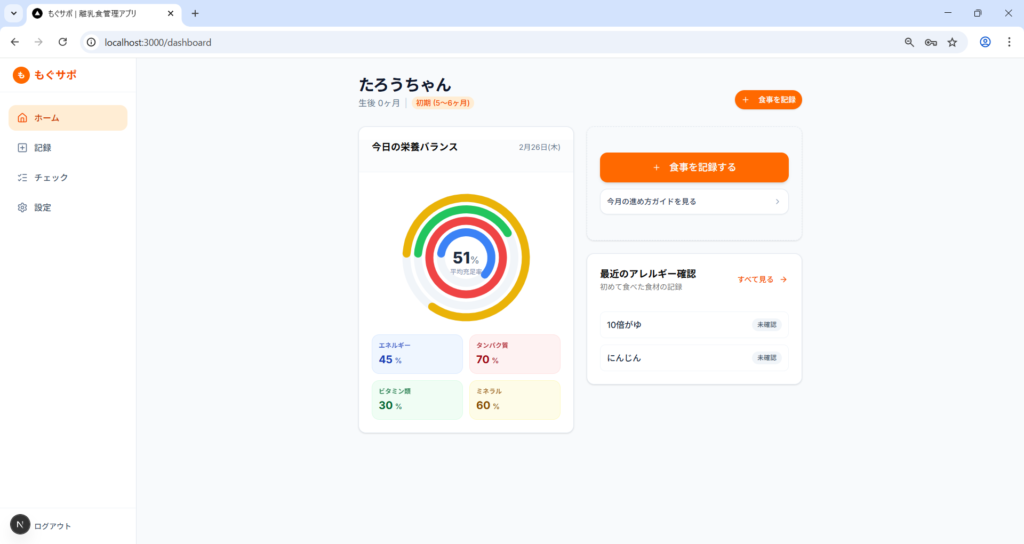
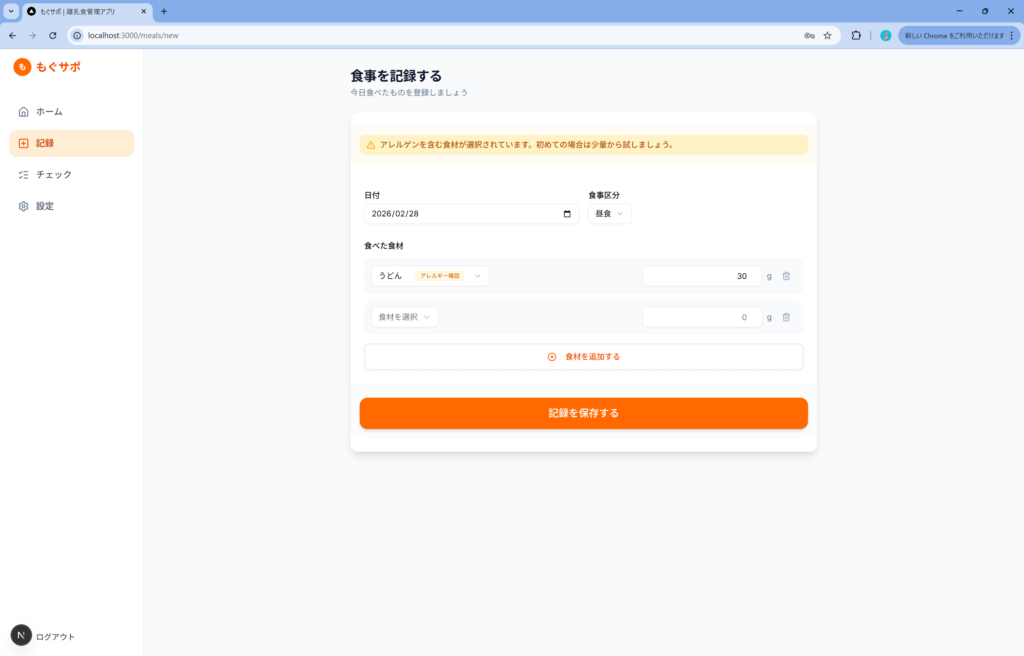
エラーが2点ありました。ログイン後に画面遷移しない問題と、Module not found エラーです。ただし、いずれも修正依頼を出したら即座に解決してくれて、デバッグ能力には問題なしという印象です。
ちゃんとレスポンシブ対応もされてます。
Claude Code(Opus 4.6)
こちらはエラーゼロで動きました。ただしUI/UXは非常にシンプルで、良く言えば堅実、悪く言えば業務アプリ感が強い仕上がりでした。
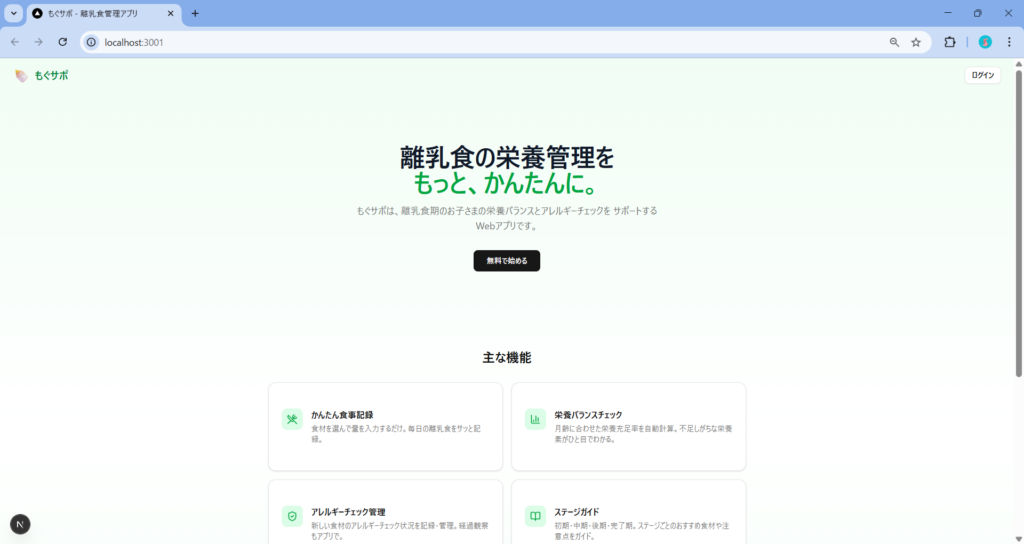
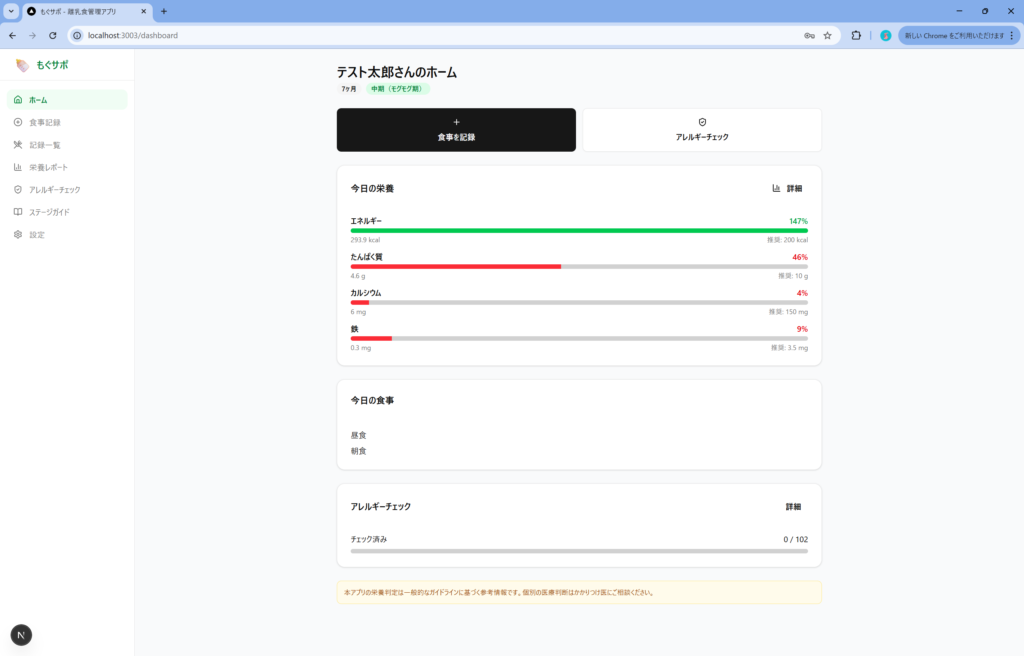
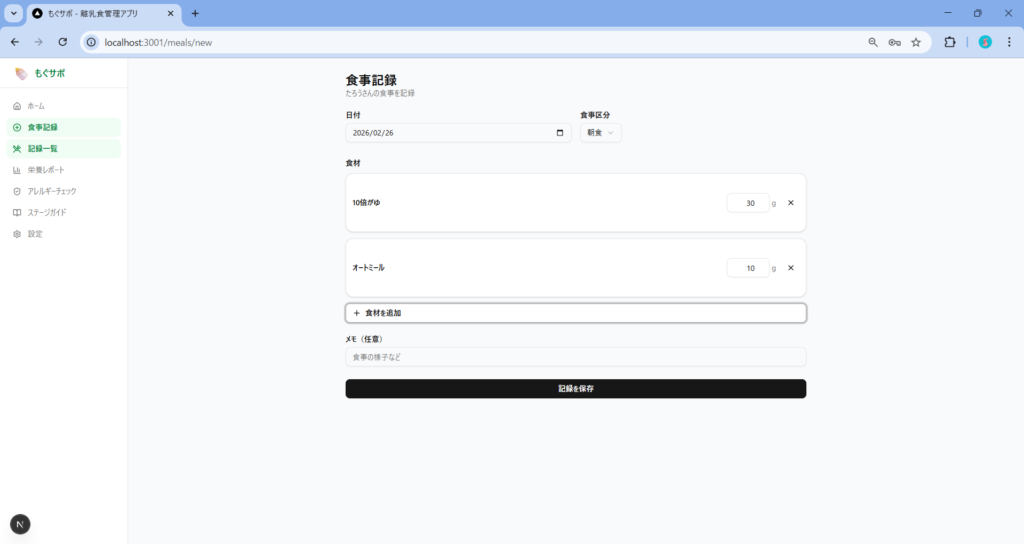
ただ食材検索機能や、栄養データの振り返り機能が一部動作しないなど、機能の網羅性にやや課題がありました。こちらは追加修正指示ですぐに修正されました。
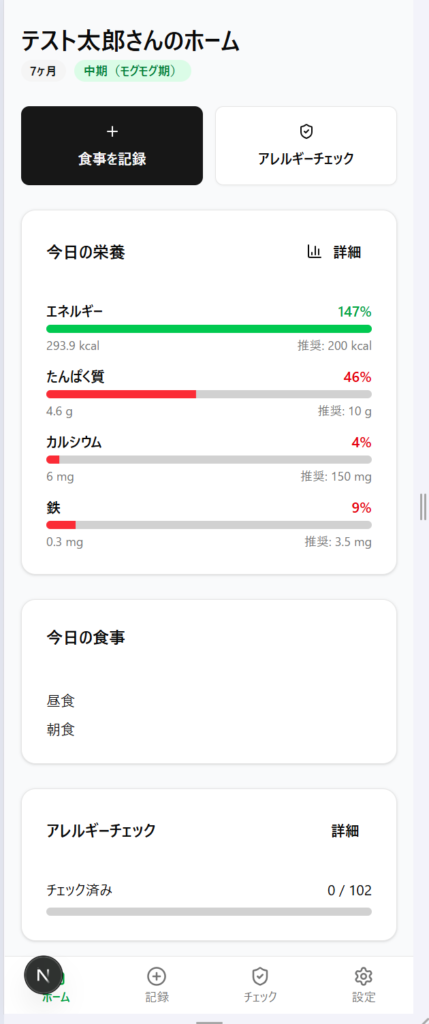
ちゃんとレスポンシブ対応もされてます。
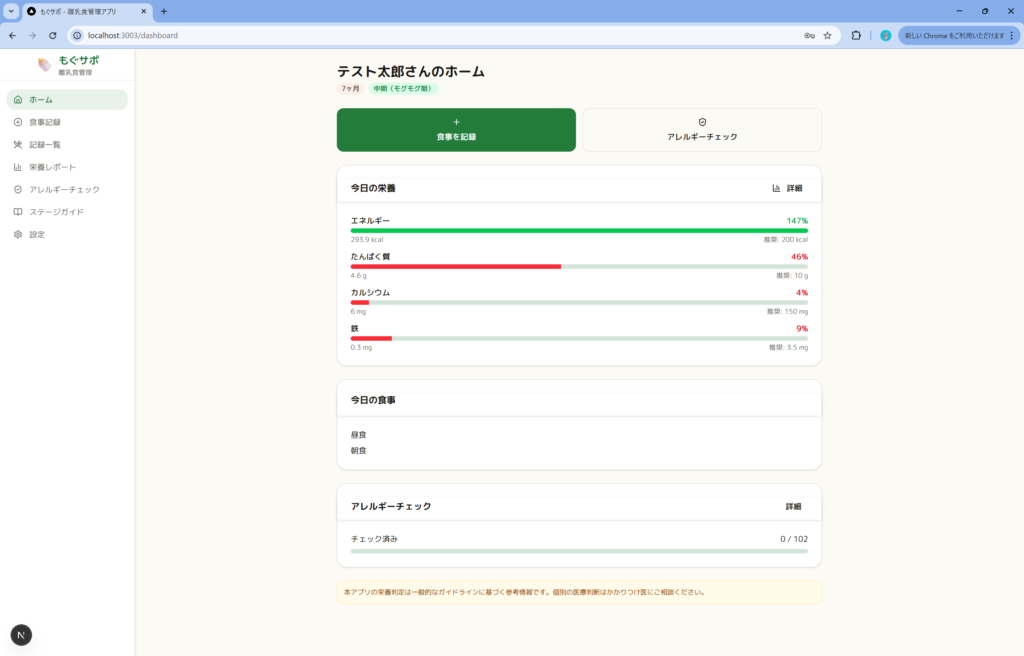
一応追加で「ターゲット層に刺さるデザインに改修してください」と指示を出しましたが、以下が出力されたので、あまりデザインは強くなさそうです。
Codex(GPT-5.3-codex)
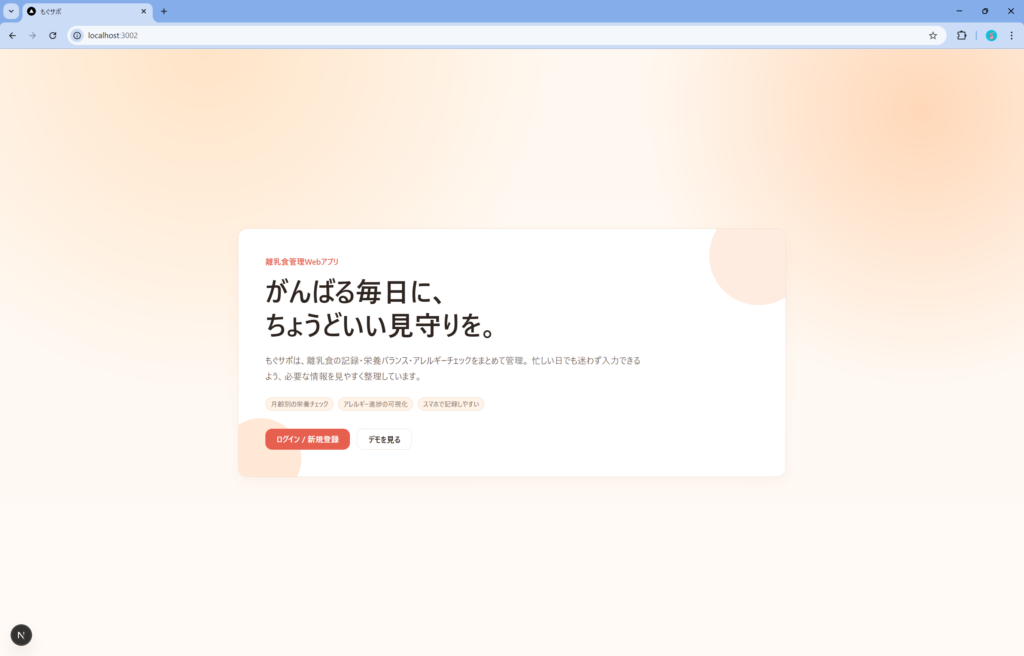
こちらは前者2つと比較してだいぶUI/UXがチープな仕上がりでした。
私としては Codex は Antigravity や Claude Code と似たものを想定していたので、意外な結果でした。
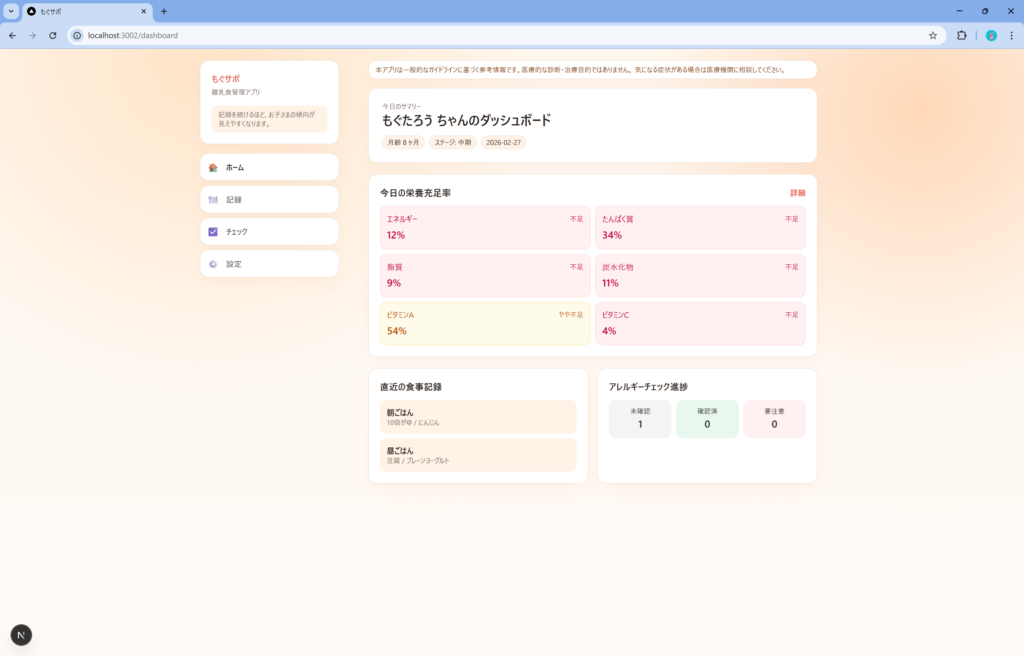
こちらも追加で「ターゲット層に刺さるデザインに改修してください」と指示を出しましたが、多少マシになった程度でデザイン面の弱さは拭えませんでした。
↓食事記録の際に食材の検索機能がなく、UXが悪い問題もありました。
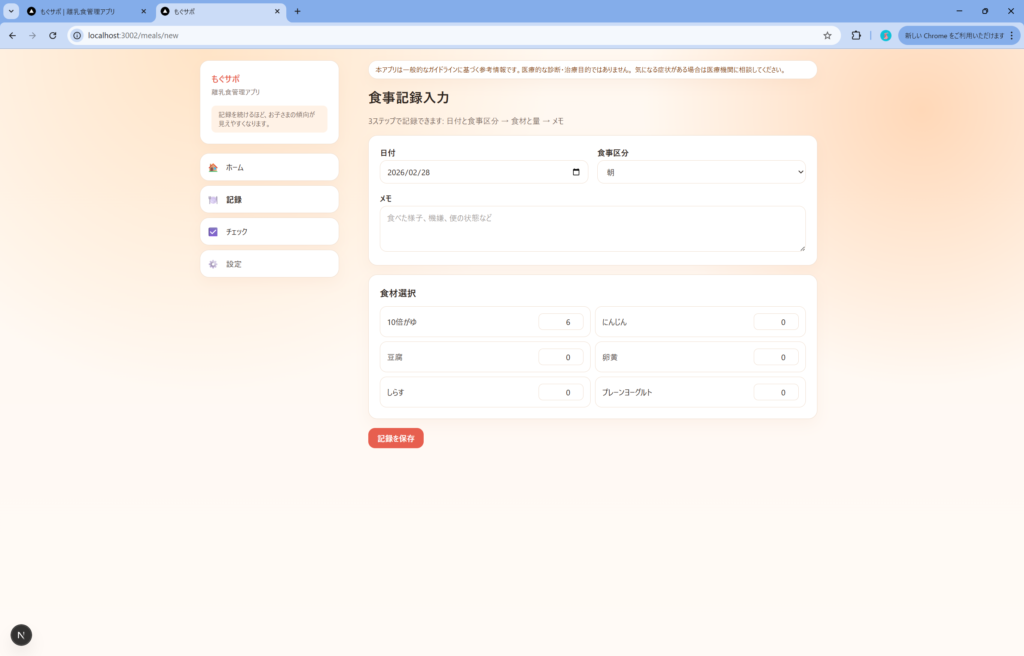
また、切りのいいところで実装を止めてしまう傾向があり、何度か続行を指示する必要がありました。エラーが1点ありましたが、こちらは追加指示ですぐに修正されました。
レスポンシブにはしっかり対応してました。
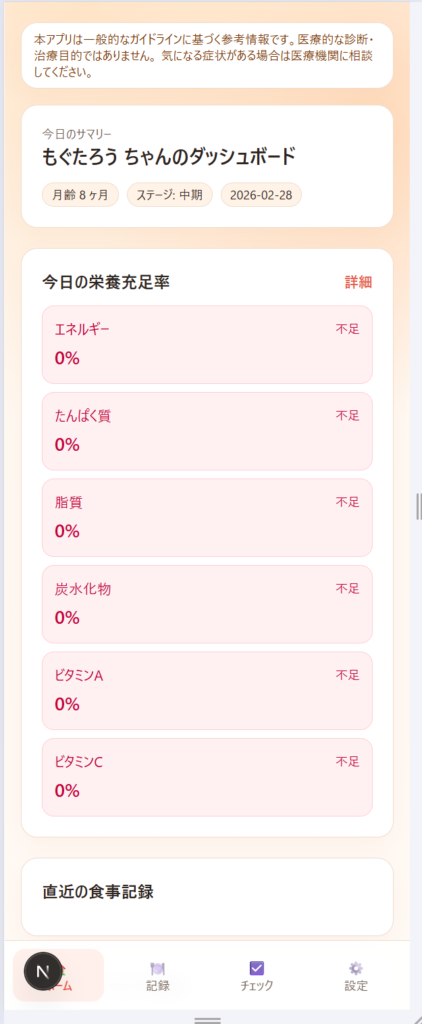
GitHub Copilot(GPT-4.1)
こちらも切りのいいところで実装が止まってしまう傾向がありました。さらに途中で発生したエラーをAgent自身が解決できず、完成を断念する結果に。今回のような12画面・10機能規模の仕様書を一括で渡すタスクは、現時点の GitHub Copilot のAgent機能には難しかったようです。
Agentとモデルの組み合わせを変えてさらに検証
Agent とモデルの関係をもう少し深掘りするため、組み合わせを変えた追加検証も行いました。
Antigravity(Opus 4.6)
Gemini 3.1 Pro でも良かったUI/UXがさらに一段上がりました。特筆すべきは、指示していないにもかかわらず framer-motion を導入し、コンポーネントにフェードアニメーションを付けていた点です。画像だとわからないのでGifにしました。
遊び心のある仕上がりで、同じ Opus 4.6 でも Claude Code とは出力がまるで違いました。エラーは1件ありましたが、こちらも指示ですぐに修正できました。
同じモデルなのにここまで差が出るということは、Agentの側のプロンプト設計やワークフローの作り込みがアウトプットに大きく影響しているということなのかなと思います。
Claude Code(Haiku 4.5)
軽量モデルなのでOpus4.6に比べてUIがチープになるのは想定内でしたが、思ったより問題なく実装されました。
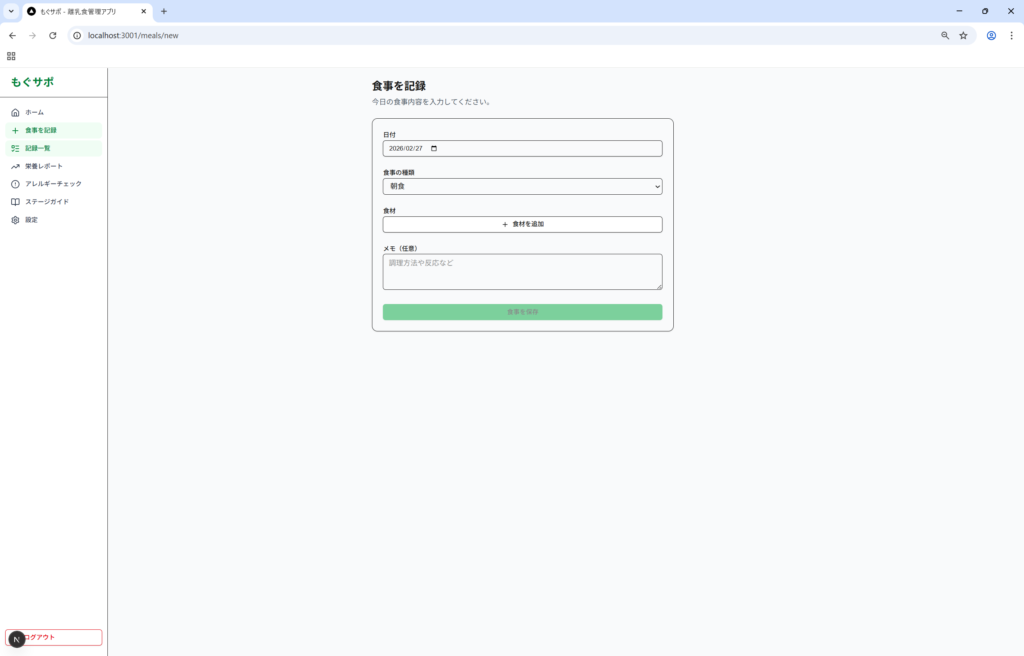
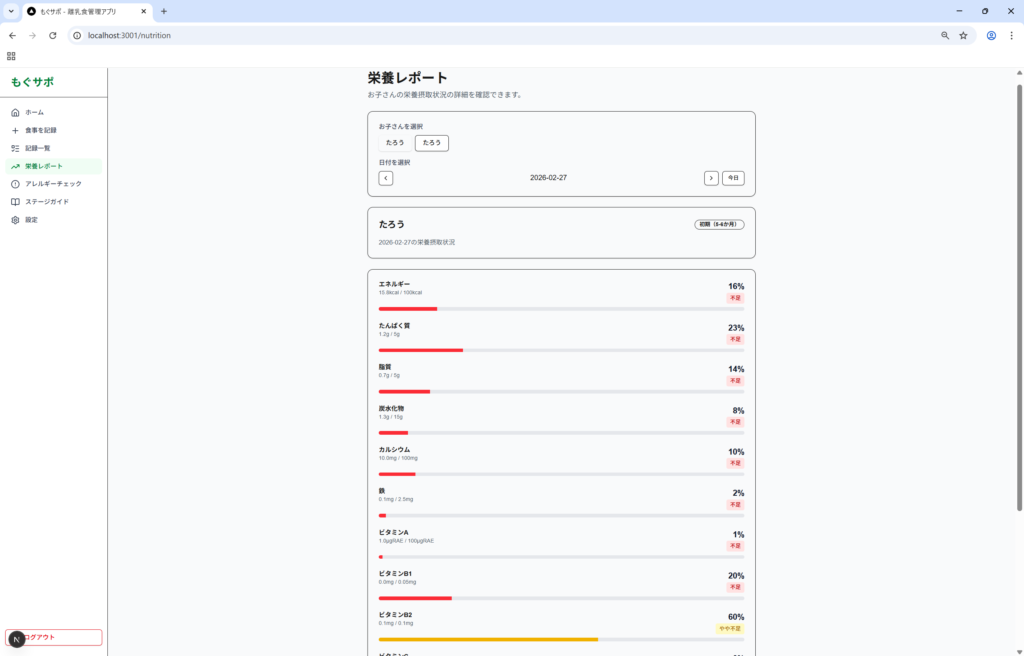
こちらも切りのいいところで止まる傾向があり、何度か続行を指示しています。エラーは2つほど発生しましたが修正依頼で即解決。出来上がりは使いやすくはないものの、最低限の機能は一通り揃っていかなという印象です。
Github Copilot CLI (Haiku 4.5)
こちらは Github Copilot のAgent機能ではなく Github Copilot CLI を利用しました。モデルは Haiku 4.5 です。
最初はcssがうまく読み込めておらず、5回の修正依頼が必要でしたが解決することができました。
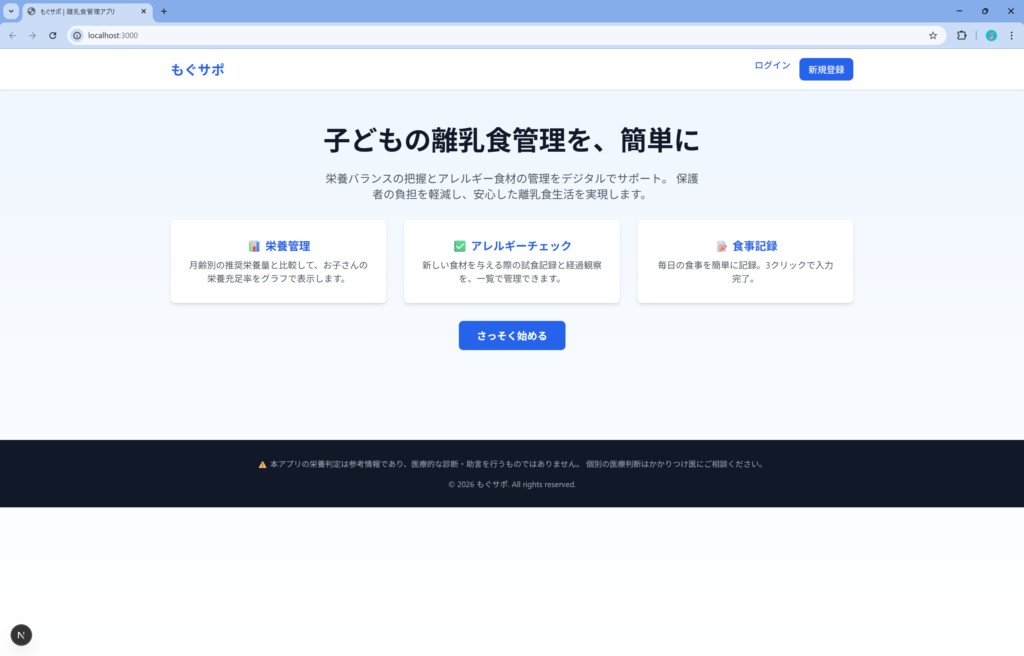
その後。子供の情報登録でバリデーションエラーになってしまったので修正依頼を出しましたが、今度はInternal Serverエラーになってしまい再修正依頼しても登録できず。。既に最初のcssの問題からだいぶ時間を食われているので結局ここで断念しました。
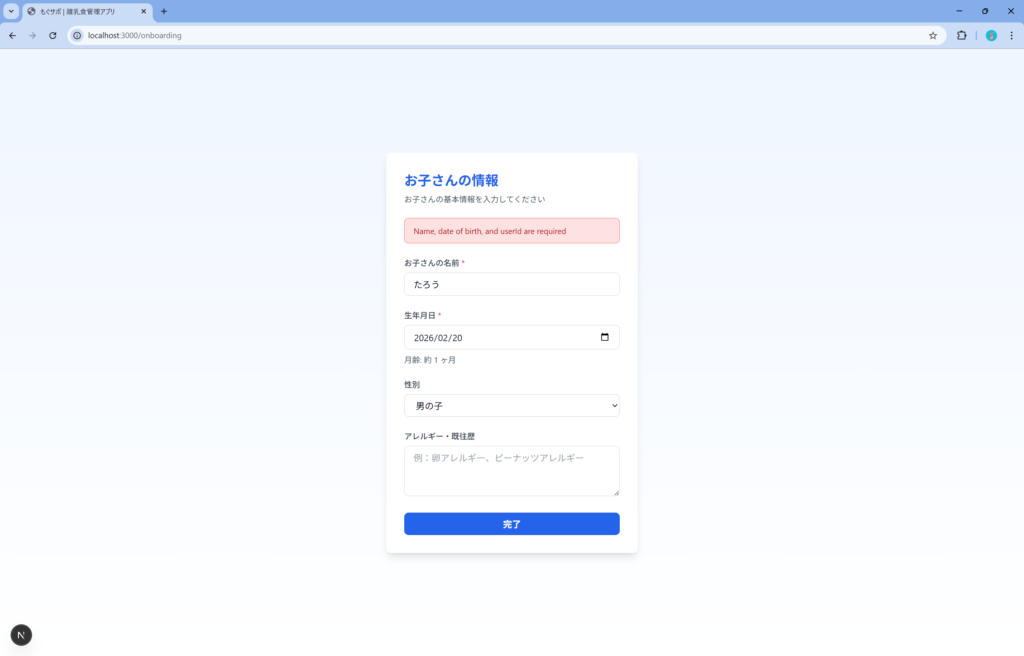
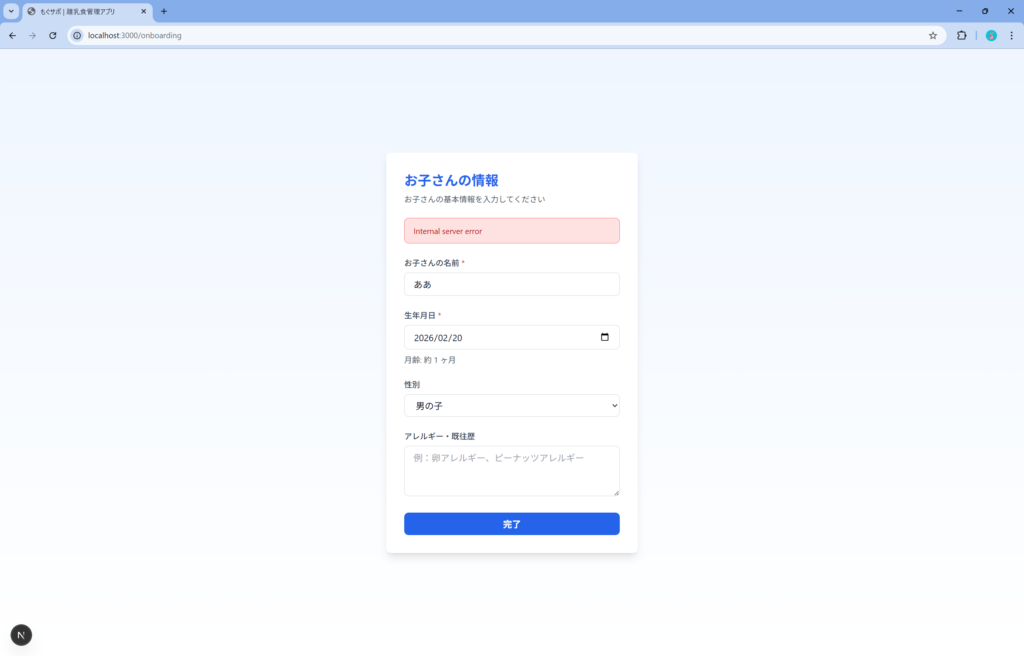
データ登録ができないので何とも言えないですが、UIの質は先ほどの Claude Code (Haiku 4.5) と同程度かなと感じました。デバッグ機能に関しては Claude Code は1発で修正してくれるような内容も、Agentが変わるだけでここまで違うか。。といった印象です。
今回の検証は Github Copilot にとってはコンテキストが大きすぎたのかもしれません。AIの特性としてコンテキストが大きすぎると単純なタスクも困難になる点があるので。
総評
モデルの差は確実に出る、しかしAgentでも意外と差が出る
上位モデル(Opus 4.6)と下位モデル(Haiku 4.5)で品質差が出るのは想定内でした。Gemini 3.1 Pro も Google の最上位モデルですが、今回の検証では Opus 4.6 の方がより高い品質のアウトプットを出しています。
しかし、同じモデルでも Agent が変わると出力が大きく変わるという発見は想定外でした。Opus 4.6 を使った Claude Code と Antigravity では、同じモデルとは思えないほどアプローチが異なりますし、Haiku4.5を使ったClaude CodeとGithub Copilot CLIでも結果が異なります。技術スタックまで仕様書で揃えているにもかかわらず、この差が出るのは Agent 側の作り込みの差と考えて良いと思います。
各Agentの所感
Antigravity は、ユーザーを想定したUI/UXの作り込みが際立っていました。指示にない部分まで想定して実装してくれるスタイルは、まさに「プロダクトエンジニア」的な振る舞いと感じました。個人的には最高でしたが、指示されたことだけを忠実にこなしてほしい人にとっては、余計な時間と、トークン消費をされたと感じるかもしれません。
Claude Code は、教科書的で堅実なUI。面白味はないものの、to Bアプリならそのまま実用できるかなと思います。いくつかの実装漏れがあったものの、軽量モデルでも完成されられる点はトークン面でも安心ですね。Antigravity と Codex の中間ってイメージ、あんまり特筆すべき点はないかな。。
Codex は、UI/UXの質は他と比べて弱い結果でした。必要最低限だけを実装するスタンスはそれだけで前者2つより好む人も多そうだなと思いました。あとは何度かやり取りが必要になり、0→1のフェーズでは効率が良くないと感じましたが、大きな手戻りを避けるという意味では途中確認を細かく挟む思想なのかもしれません。Codex についてまとめると、バイブコーディング向けではなさそうかな。ネット上の意見だとコードレビューが強いみたいで、レビュー用Agentとして使用している人も多いようです。
GitHub Copilot (Agent or CLI) は、今回のような大きな仕様書ベースの開発には不向きでした。コンテキストの大きさが原因なのか、AgentもCLIも完成に至りませんでした。CLIに関しては Claude Code で実装できたモデルと同じ Haiku4.5 だったので結構衝撃。Agent機能はあれど、あくまでもコーディング支援という位置づけなのかなと思いました。
おまけ:ちょっと気になる構図の話
ここから先は完全に個人の雑感です。
Microsoft はAI初期は買収した GitHub に Copilot を作らせている一方で、途中巨額出資先の OpenAI が Codex を世に放ち、結果的に競合を自ら生み出しています。最近 Azure 上で Codex が使えるようになったという話もあり、時系列で構図を追っていくと、GitHub Copilot が Microsoft の戦略の中でどういう位置づけになっていくのか。。IDEとの統合や、Github との連携での差別化は各社Agentの進化でだいぶ薄れてきてるし、コーディング支援の立場は、コーディングAgentに置き換わるんじゃ……おっと、誰か来たようだ
追記
なんとGithub Copilotのサブスクリプション内でClaudeとCodexのAgentが使えるようになったみたいです。これが唯一の生き残り方だったのかもしれない。
本記事は特定のツールを推奨・否定するものではなく、あくまで個人の検証結果に基づくものです。各ツールはアップデートにより日々改善されています。
※この記事の執筆には一部生成AIが使用されています

